


The Breker Trekker Tom Anderson, VP of Marketing
Tom Anderson is vice president of Marketing for Breker Verification Systems. He previously served as Product Management Group Director for Advanced Verification Solutions at Cadence, Technical Marketing Director in the Verification Group at Synopsys and Vice President of Applications Engineering at … More » Why Is Cache Coherency So Hard to Verify?February 19th, 2016 by Tom Anderson, VP of Marketing
In last week’s post, we provided a preview of the program at the annual Design and Verification Conference and Exhibition (DVCon) in San Jose, coming up in ten days. We mentioned some of the interesting talks and other activities there, and focused in particular on “Using Portable Stimulus to Verify Cache Coherency in a Many-Core SoC” on Tuesday morning. The paper for this session was co-authored by Breker and Cavium, and both companies will present together at DVCon. The paper and presentation describe the use of our Cache Coherency TrekApp and TrekSoC-Si to automatically generate self-checking, portable test cases for more than 100 CPU cores in a multi-SoC configuration in the Cavium bring-up lab. To set the stage for this story, today we’d like to revisit some of the reasons why cache coherency is so hard to verify and why an automated approach is the best solution.
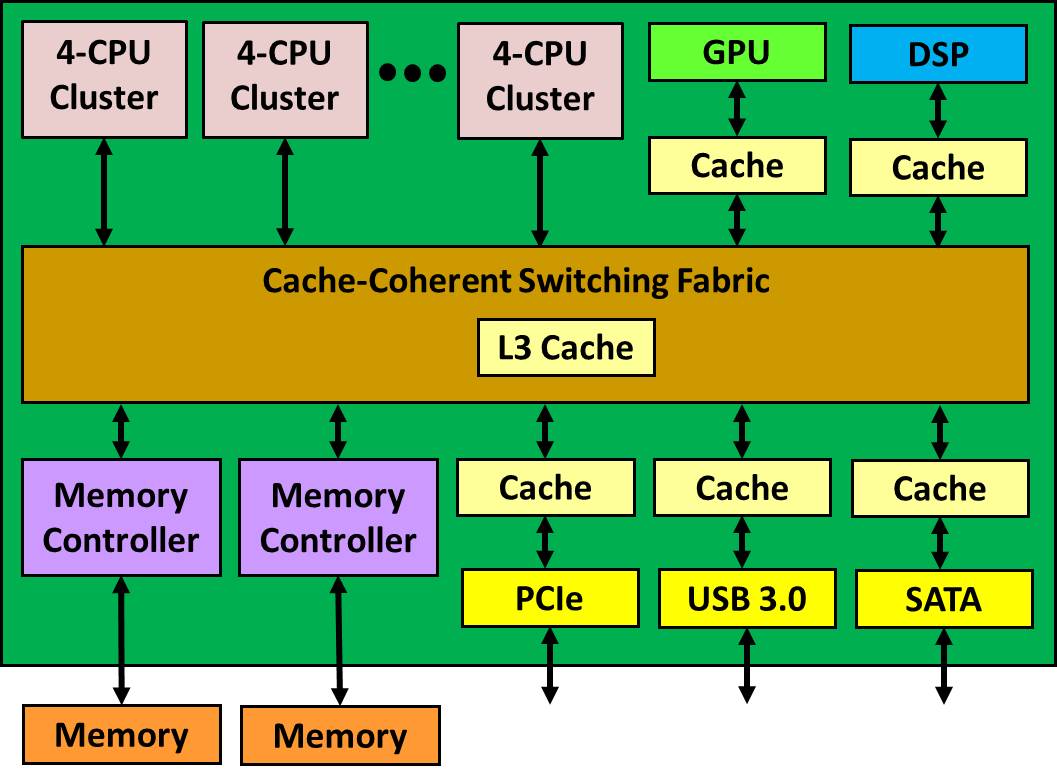
We have discussed at some length how the chip industry is evolving to multiprocessor SoC designs with multiple levels of caches and cache-coherent interconnects. The CPU vendor typically provides a cluster of 4-8 processors, each with its own level 1 (L1) cache and a shared level 2 (L2) cache. The SoC may contain an L3 cache, other cache-coherent agents, and interfaces that must be I/O-coherent. The result often looks much like the following diagram:
Among other reasons, proper interprocessor communication using flags depends on this ordering being correct. A read may involve accessing other caches in the same cluster, accessing caches other clusters, or accessing the L3 cache. In fact, there are many possible ways that cache states can transition depending upon where data resides and who has permission to modify it. These transitions are governed by a cache coherency protocol, for example the popular MOESI scheme:
It is challenging enough to verify all the state transitions for a single processor and a single cache. In a multiprocessor SoC, combinations of state transitions must also be verified. But this just scratches the surface. In fact, all the following items must be verified both individually and in cross-combinations:
Non-determinism is at the root of the difficulty of verifying full-SoC cache coherency. Except in very simple cases, it’s impossible to predict exactly which cache transitions will happen when. Memory timing, refresh cycles, memory controller congestion, interconnect saturation, and other factors can affect cache behavior. It is almost impossible to imagine hand-writing interacting, self-checking cache coherency tests for a multiprocessor SoC running one on platform, let along making these tests portable. Breker’s approach to cache coherency is a very welcome alternative. The cache protocol is captured in a graph-based scenario model. Breker’s tools can then automatically generate multi-threaded test cases that cross back and forth among the processors while exercising all cache transitions and covering the items listed above. These test cases can be generated to run on any verification platform, from simulation to silicon. To find out more details in the context of a real Cavium design, please attend our DVCon presentation. Thanks! Tom A. The truth is out there … sometimes it’s in a blog. Tags: application, Breker, bring-up lab, cache coherency, Cavium, dvcon, emulation, FPGA, functional verification, graph, graph-based, MOESI, multi-SoC, node coverage, path coverage, portable stimulus, protocol, prototyping, PSWG, realistic use case, scenario model, simulation, SoC validation, SoC verification, system-on-chip, test case generator, test cases, TrekSoC-Si, Universal Verification Methodology, use-case coverage, uvm Warning: Undefined variable $user_ID in /www/www10/htdocs/blogs/wp-content/themes/ibs_default/comments.php on line 83 You must be logged in to post a comment. |
|
|
|||||
|
|
|||||
|
|||||





 Animation, 3D Art and 3D Models")