Not surprisingly, several news this week are somewhat related to fabs and foundries – in terms of customer contracts, new fabs, acquisitions, equipment – as companies around the world are repositioning to take advantage of the semiconductor boom. Another interesting update concerns Simon Segars speaking about the Nvidia deal. More news is coming from the International Supercomputing Conference and from the latest MLPerf results.
Apple and Intel reportedly first to adopt TSMC’s 3 nm process
According to Nikkei Asia, Apple and Intel have emerged as the first adopters of TSMC’s 3-nanometer process ahead of its deployment as early as next year. Commercial output of such chips is expected to start in the second half of next year. Apple’s iPad will likely be the first devices powered by processors made using 3-nanometer technology. Intel is reportedly working with TSMC on at least two 3-nanometer projects concerning CPUs for notebooks and data center servers. Mass production of these chips is expected to begin by the end of 2022 at the earliest. Reportedly, the chip volume planned for Intel is more than that for Apple’s iPad.
Not just lithography: scaling to 2-nanometers and beyond involves many difficult manufacturing challenges. A virtual event and a series of blog posts from Applied Materials help understand how these problems can be solved with coordinated solutions based on new transistor architectures, new materials, new manufacturing processes
Over the past few years, the transition to EUV lithography has received a lot of attention as a key enabling technology for further IC scaling. But moving to the next advanced process nodes is not just about projecting smaller patterns; in fact, the resulting size reduction of every circuit feature opens a set of new, complex problems that need to be addressed in order to achieve the expected PPA benefits. Let’s take a look at these challenges with the help of Applied Material’s experts. In a ‘Logic Master Class’ held as a virtual event last June 16th – still available on demand – and in a series of related blog posts, Mike Chudzik, Mehul Naik and Regina Freed addressed different aspects of the scaling of logic ICs, stressing the increasing importance of ‘design-technology co-optimization’ (DTCO). Applied Materials describes DTCO as a way to “reduce area-cost without changing the lithography and pitch,” using a combination of architectures, processes and materials. In this quick overview of the class, we will only summarize some of the general concepts.
Pitch scaling is not enough
The need for innovation stems from the fact that just building a smaller version of the same device – as in the traditional method, called pitch scaling or ‘intrinsic scaling’ – would lead to bad power and performance results and to increased device variability. This is because size reduction generates new limiting factors. Trying to generalize, one could say that there are mechanical limitations, electrical limitations, and process limitations. Mechanical limitations include the fact that some elements may become too weak to withstand mechanical stress; electrical limitations mostly refer to the increased resistance of current paths – signal or power – due to smaller cross section area; and process limitations include the fact that certain specific elements – e.g. certain material layers – cannot scale proportionally, or that patterning inaccuracy become a larger percentage of the intended feature. Collectively, these limitations are now determining the transition from FinFET to GAA (Gate-All-Around) transistors.
According to industry association SEMI, semiconductor manufacturers around the world will start the construction of nineteen new high-volume fabs by the end of this year, and ten more fabs will be added in 2022. So it’s no surprise that several announcements this week concern new fabs. Besides rumors about a new European site, Intel is in the news also for its organizational changes that – to some extent – reflect the growing importance of AI and hyperscale data centers. Among other news is a further advancement of machine learning in EDA-related technologies, namely FPGA design tools; and a new manufacturing process enabling further scaling.
Intel reportedly in talks on a new fab near Munich, Germany
Intel is reportedly in talks with the German state of Bavaria to build a new fab, with the goal of countering the chip shortage that is damaging the automotive industry. According to the report, in recent months Intel has been seeking 8 billion euros (US$9.5 billion) in public subsidies to build a semiconductor manufacturing site in Europe. Reportedly, the Bavarian Economy Minister is strongly supporting the initiative. The Bavarian government has suggested a disused air base in Penzing-Landsberg, west of Munich, as a possible location for the factory. The German state of Bavaria is home to carmaker BMW, and the Munich area is a significant semiconductor manufacturing hub, hosting – among others – a large Texas Instruments factory.
Acquisitions stand out in this week’s news roundup, catching up on some of the updates from the last fifteen days or so. But first, some interesting news about the evolution of the processor industry landscape, the use of deep learning in chip design, and foundry roadmaps.
Intel reportedly considering SiFive acquisition
The Nvidia-Arm deal – still under regulatory scrutiny – and the recent appointment of Pat Gelsinger as new Intel CEO are two factors that keep shaking the processor industry. Intel is reportedly considering the acquisition of SiFive, in a move that would enable the Santa Clara giant to add a rich portfolio of Risc-V-based IP, an open-source alternative to Arm. As noted in another report, with the acquisition Intel would also gain a software boost thanks to SiFive experts such as Chris Lattner. Meanwhile, concerns about the Nvidia-Arm deal start to emerge publicly. Qualcomm President Cristiano Amon has reportedly said that – in case SoftBank decides to launch an IPO for Arm – his company and many others would be interested in buying a stake.
Cristiano Amon. Credit: Qualcomm
Google’s research work on deep learning-based chip floorplanning: updates
Preceded in April 2020 by a preprint posted on the online arXiv repository, the paper from Azalia Mirhoseini and other Google researchers about deep learning- based chip floorplanning has recently been published by Nature magazine – with the addition of methods that improve results and that have been used in production to design the next generation of Google TPUs. One year after preprint, the topic cannot be considered ‘news’ anymore – but it’s definitely worth attention. Quoting from the paper abstract: “In under six hours, our method automatically generates chip floorplans that are superior or comparable to those produced by humans in all key metrics, including power consumption, performance and chip area.
The importance of a holistic system-level approach was one of the common themes across the keynotes speeches given by top executives and guests at CadenceLIVE Americas 2021, a virtual event held on June 8 and 9. Machine learning, of course, was a major topic too – both in terms of new product announcements and R&D directions.
The ‘semiconductor renaissance’ and the role of hyperscalers
Cadence CEO Lip-Bu Tan opened the event by discussing the theme of ‘semiconductor renaissance’, the current silicon boom fueled by 5G, autonomous vehicles, industrial IoT, AI/ML. “It’s the first time we have multiple strong drivers at the same time,” he noted. “A few years ago, people were thinking semiconductor was a slowing, sunset industry, but not anymore. (…) We are currently facing a supply chain issue, but it’s due to overwhelming broad base demand. It is a great time to be in the semiconductor and electronics industry.” In his speech, Lip-Bu Tan devoted a special attention to the role of hyperscalers. “Hyperscalers are at the center of the renaissance and data revolutions,” he said. “Massive CAPEX spend, estimated at over 120 billion last year; over six hundred hyperscale data centers, with over a hundred opened in pandemic year 2020,” he pointed out. “[Hyperscalers[ participate in all stages of the data cycle and are pushing the need for innovation in technologies across computer, memory, storage and networking. (…) Hyperscalers are also pushing the most advanced process nodes, focus on the latest IP protocols (…). And they need advanced packaging, and also a lot of system-level simulation. It’s not just about chips to meet their needs; system level optimization across compute, networking and other hardware is needed, but also software needs to be co-optimized.” Among other things, Lip-Bu Tan also underlined the growth opportunities offered by data analysis and edge computing. Providing a general overview of all Cadence business, he also mentioned that Cadence Cloud is being used by over 175 customers.
New materials, new transistor structures, new integration schemes: many of the boost scaling options being investigated by research teams around the world will be represented at the 2021 Symposia on VLSI Technology & Circuits – running as a virtual event from June 13 to 19. Just as a teaser, in this article we will briefly summarize a handful of papers from the Technology program, to give a taste of some current research trends.
Benefits of forksheet over nanosheet
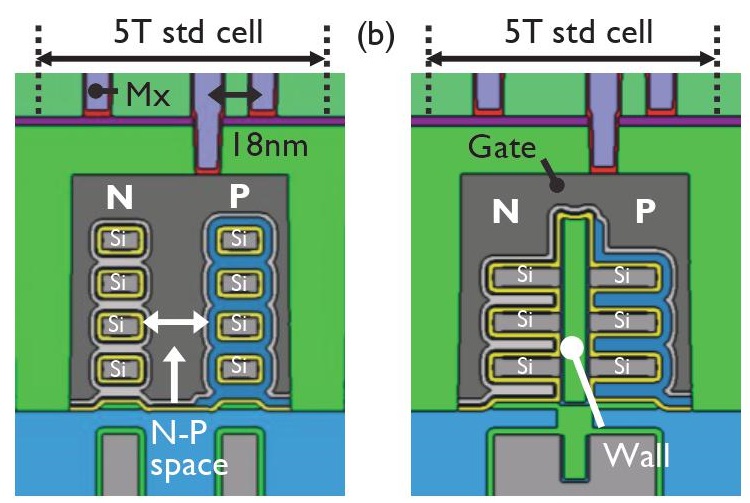
One of the papers presented by Belgian research institute Imec is meant to demonstrate the benefits of forksheet transistors over nanosheet transistors for CMOS area scaling. Forksheet devices are lateral nanosheet devices with a forked gate structure. The physical separation of N- and PFETs by a dielectric wall enables N-P space scaling and consequently sheet width maximization – compared to a N-P nanosheet configuration – for the same footprint. According to Imec, forksheet transistors offer additional benefits in the manufacturing process. Firstly, for nanosheets the high mask aspect ratio is challenging for patterning a well-defined N-P boundary over the full stack height. Secondly, the pWFM (Work Function Metal) lateral etch in-between NMOS nanosheets can lead to mask undercut and therefore pWFM removal from PFETs. For forksheet devices, the mask aspect ratio at the N-P boundary is substantially lower because the mask edge lands on top of the wall. In addition, the risk of pWFM removal from PFETs due to mask undercut is eliminated by the physical separation of the pWFM on either side of the wall, including along the gate trench side walls. Electrostatic control for forksheets and nanosheets is comparable.
Nanosheet (left) vs forksheet (right) comparison. Source: 2021 VLSI Symposia
Chip shortage and foundry activity continue to make headlines. Tesla is reportedly considering paying in advance for chips to secure its supply, and is said to be even exploring the acquisition of a semiconductor fab. GlobalFoundries is reportedly working with Morgan Stanley on an initial public offering that could value the foundry at about $30 billion. Let’s now move to some process technology and EDA updates.
Vertical nanowire-based memory promises 4X DRAM density without special materials
Singapore-based Unisantis unveiled the developments of its Dynamic Flash Memory (DFM) technology at the recent IEEE International Memory Workshop. According to the company, DFM offers faster speeds and higher density when compared to DRAM or other types of volatile memory. DFM is also a type of volatile memory, but since it does not rely on capacitors it has fewer leak paths, and it has no connection between switching transistors and a capacitor. The result is a cell design with the potential for significant increases in transistor density. Additionally – as it offers ‘block erase’ like a Flash memory – DFM reduces the frequency and the overhead of the refresh cycle and can deliver significant improvements in speed and power compared to DRAM. Based on TCAD simulation, Unisantis claims that DFM can potentially achieve a 4X density increase compared to DRAM. So, while the scaling of DRAM has almost stopped at 16Gb, DFM could be used to build 64Gb memory devices. Unisantis points out that unlike the so-called ‘emerging memory technologies’ (MRAM, ReRAM, FRAM, PCM), its Dynamic Flash Memory does not require using additional materials on top of a standard CMOS process. DFM was developed by Unisantis with the principles of its patented surround gate transistor (SGT) technology, also referred to in the semiconductor industry as a vertical nanowire transistor. According to the company, the benefits of this technology include improved area density, compared to planar and FinFET transistors; reduced leakage power, due to the strong electrostatic control of the surrounding gate to the transistor channel; and the possibility of optimizing the transistor width and length for different power/performance combinations. Unisantis is working on SGT technology in collaboration with Belgian research institute Imec.
Chip shortage and new fab plans continue to be hot topics this week, while there is no shortage of AI news – with Google announcing the next generation of TPUs, and Edge Impulse expressing an interesting concept about machine learning bound to replace code writing in algorithm design.
Chip lead times reach 17 weeks
According to a research by Susquehanna Financial Group, quoted by Bloomberg, chip lead times – the gap between order and delivery – increased to 17 weeks in April. That is the longest wait since the firm began tracking the data in 2017. Specific product categories reported even longer lead times: 23.7 weeks in April for power management chips, about four weeks more than a month earlier; industrial microcontrollers also showed a worsened situation, with order lead times extended by three weeks. Automotive chip supply continues to be a pain point, with NXP reportedly having lead times of more than 22 weeks now – up from around 12 weeks late last year – and STMicroelectronics to more than 28 weeks. This situation is raising concerns of ‘panic ordering’ that may lead to market distortions in the future.
Catching up on some of the news from the last four weeks or so, the IBM 2-nanometer announcement definitely stands out as a major update. Several recent news also concerns EDA, as well as AI accelerators. Two of the newest updates about AI startups will translate into an additional $150 million pumped into this industry by investors.
IBM’s 2-nanometer chip
As widely reported by many media outlets, last May 6 IBM announced the development of the world’s first chip with 2-nanometer nanosheet technology. The result was achieved by IBM research lab located at the Albany Nanotech Complex in Albany, NY, where IBM scientists work in collaboration with public and private sector partners. According to the company, IBM’s new 2-nanometer chip technology will achieve 45 percent higher performance, or 75 percent lower energy use, than today’s most advanced 7-nanometer node chips. Reporting about the announcement, EETimes underlined that this chip is the first to use extreme-ultraviolet lithography (EUV) for front-end of line (FEOL) processes. Other details reported by EETimes include the use of bottom dielectric isolation to eliminates leakage current between nanosheets and the bulk wafer; and a novel multi-threshold-voltage scheme. Reportedly, IBM expects 2-nanometer foundry technology based on this work to go into production towards the end of 2024.
2 nm technology as seen using transmission electron microscopy. Courtesy of IBM.
Cerebras’ new 2.6 trillion transistors wafer scale chip is one the announcements made during the 2021 edition of the Linley Spring Processor Conference, a virtual event organized by technology analysis firm The Linley Group from April 19 to 23. In our quick overview of the conference we will focus mainly on new product announcements, which include innovative AI intellectual property from startups Expedera and EdgeCortix, a new approach to clock distribution from Movellus, and more. But first, let’s briefly summarize the opening keynote given by Linley Gwennap – Principal Analyst of The Linley Group – who provided an updated overview of AI technology and market trends.
A variety of AI acceleration architectures
Gwennap described the different AI processing architectures that the industry has developed over the past few years. While many CPUs, GPUs, and DSPs include wide vector (SIMD) compute units, many AI accelerators use systolic arrays to break the register-file bottleneck. Also, convolution architecture optimized for CNNs have been proposed: examples include processors developed by Alibaba and Kneron. Within AI-specialized architectures, many choices are possible: a processor can use many little cores, or a few big cores. Extreme examples are Cerebras with its wafer-scale chip integrating over 400,000 cores (850,000 in the latest version), and Groq with one mega-core only. Little cores are easier to design, while big cores simplify compiler/software design and are better for real-time workloads. Another architectural choice is between multicore versus dataflow: in a multicore design, each core executes the neural network from start to finish, while in a dataflow design the neural network is divided across many cores. An additional architectural style – that goes ‘beyond cores’ – is Coarse-Grain Reconfigurable Architecture (CGRA), which uses dataflow principles, but instead of cores, the connected blocks contain pipelined compute and memory units. This approach has been adopted by SambaNova, SimpleMachines, Tsing Micro and others. So the industry now offers a wide range of AI-capable architectures, ranging from very generic to very specialized. In general terms, a higher degree of specialization translates into higher efficiency but lower flexibility.












 Animation, 3D Art and 3D Models")