


EDACafe Editorial Roberto Frazzoli
Roberto Frazzoli is a contributing editor to EDACafe. His interests as a technology journalist focus on the semiconductor ecosystem in all its aspects. Roberto started covering electronics in 1987. His weekly contribution to EDACafe started in early 2019. Linley Fall Processor Conference 2020 – Part OneOctober 27th, 2020 by Roberto Frazzoli
Despite the virtual format, the 2020 Fall edition of the Linley Processor Conference – organized by the technology analysis firm Linley Group – is offering its biggest program ever, with 33 technical talks across six days: October 20 to 22, and October 27 to 29. The high number of presentations confirms that these are really exciting times for innovative processing architectures. In his keynote, Linley Gwennap – Principal Analyst of The Linley Group – explained the proliferation of application-specific accelerators describing them as a way to extend Moore’s Law, since moving to the most advanced process nodes now offers little benefit. In this article, EDACafe is providing a quick overview of some of the presentations which were given during the first part of the event, mainly focusing on new announcements; next week we will complete our coverage with an overview of the second part of the conference. AI-specific architectures: Flex Logix, Brainchip, Groq, Hailo, Cornami Flex Logix’s InferX X1 chip, announced at the 2019 Linley Fall Conference, is now available. According to the company, the device is 3-18 times more efficient than Nvidia’s GPU architecture for large models with megapixel images, and is also much more efficient in terms of throughput per square millimeter of die area: it measures 54mm2 compared to 545mm2 for Nvidia Tesla T4. Flex Logix claims that the InferX X1 runs faster than Nvdia’s Xavier NX on real customer models at much more attractive prices: from $99 to $199 (1KU quantity), depending on speed grade.  Credit: Flex Logix Brainchip, which offers a neuromorphic System-on-Chip introduced at last spring edition of the Linley Conference, has added details on “activation sparsity” and “activity regularization”. Activation sparsity is the percentage of zero-valued entries in the previous layer’s activation maps; higher activation sparsity yields fewer operations. CNNs converted to event-domain (i.e. spiking networks) automatically start at 40-60% activation sparsity due to the use of ReLU and batch normalization; Brainchip further increases activation sparsity by using activity regularization during training. Activity regularization is the process of adding more information to the loss function to balance the model’s accuracy and activation sparsity. Increasing activation sparsity, activity regularization further reduces computation.
Groq, which described its Tensor Streaming Processor chip (TSP) at the last spring Linley Conference, has recently started shipping its system solutions to customers worldwide: Groq card, Groq node and Groq ware SDK.  Credit: Groq According to Hailo, the processing performance required by deep learning vision applications in vehicles calls for domain-specific architectures. But effective architectural disruption requires extensive domain understanding. Deriving the energetic efficiency of a processor (TOPS/W) from rated compute capacity and rated power – ignoring measured functioning data – can lead to incorrect results. Hailo is addressing the stringent compute and efficiency requirements posed by automotive applications with its Hailo-8 device, described as “the world’s most powerful and efficient edge AI processor”- providing 26 TOPS, 3 TOPS/W.  Credit: Hailo At the 2019 Linley Fall Processor Conference, Cornami introduced the concept of a dynamically reconfigurable systolic array, citing application examples from future automotive sensor processing needs. Now Cornami is raising the bar addressing real-time Fully Homomorphic Encryption. FHE allows information to be processed while encrypted, making it possible to exploit untrusted network/compute resources. But real-time FHE requires very high processing performance. Cornami claims that its new computational fabric is up to the task. AI-optimized foundry processes Globalfoundries showcased its AI-optimized offering. According to GF, process scaling is becoming increasingly ineffective to reduce cost and power; the best PPA results can actually be achieved with 12nm or 22nm process nodes, with careful optimization of all aspects that are specific to AI accelerators. Globalfoundries offers two different AI-suitable CMOS technologies: 12LP/12LP+ (FinFET) for cloud and edge server applications; and 22FDX (FD-SOI, planar transistor) for edge devices. Optimizations for the 12LP+ process allowing lower power include “dual work function gates”, while for both 12LP and 12LP+ Globalfoundries offers an “AI Accelerator Custom Core reference package” that includes logic library enhancements for AI, logic PPA optimizations (such as optimization of MAC units), design analysis, low voltage SRAM solutions, custom memory solutions. Sample Globalfoundries customers for the 12LP/12LP+ FinFET-based process include Tenstorrent and Enflame. The other Globalfoundries technology, 22FDX, enjoys the benefits of FD-SOI, and the AI-optimized offering in this case includes a body-bias ecosystem, an automotive-qualified solution, and an eMRAM storage solution. Sample Globalfoundries customers for the 22FDX process include Perceive and Greenwaves. Risc-V-based processors: Think Silicon, SiFive, Andes Besides AI-specific architectures, some of the presentations given at the conference concerned Risc-V-based processors. Greece-headquartered Think Silicon, an Applied Materials company, presented a preview of its Neox family of GPUs based on the Risc-V ISA, for graphics, compute and AI workloads. The new processor cores feature a combination of graphic vector Risc-V ISA extension and customized user defined instructions. When used with Risc-V CPU cores, Neox GPUs leverage common compiler technologies and facilitate workload balancing. The Neox family includes three GPUs with four, sixteen and sixty-four cores, respectively. SiFive introduced its new Linux-capable VIU7 core IP based on Risc-V with Vectors (RVV). The processor is based on RVV v1.0, an open industry standard ISA which – according to SiFive – offers many benefits and enables efficient SoC Implementation: a GPU or DSP is no longer required for most applications. RVV also provides a binary-compatible platform starting from tiny embedded cores to supercomputer-class multicore clusters, and streamlines software development. According to SiFive, VIU7 offers a 6.3X speedup over Arm Cortex-A53 for a specific computer vision task, and a 4.3X speedup over Arm Cortex-A53 for MobleNet V1. Andes reiterated the features of its NX27V, a processor that the company introduced on December 2019 at the RISC-V Summit. Based on Risc-V Vector Extension and manufactured in a 7nm process, the NX27V – according to Andes – outperforms Arm A64FX on several fronts. A new safety-capable Arm core The recently introduced Cortex-A78AE was the subject of Arm’s presentation. It’s the latest, highest performance “safety-capable” Arm CPU, offering the ability to run different, complex workloads for autonomous applications such as mobile robotics and driverless transportation. It delivers a 30% performance uplift compared to its predecessor, and supports features to achieve the relevant automotive and industrial functional safety standards, ISO 26262 and IEC 61508 for applications up to ASIL D / SIL 3. Its new Split Lock functionality (Hybrid Mode) is designed to specifically enable applications that target lower levels of ASIL requirements without compromising performance and allow the deployment of the same SoC compute architecture into different domain controllers. 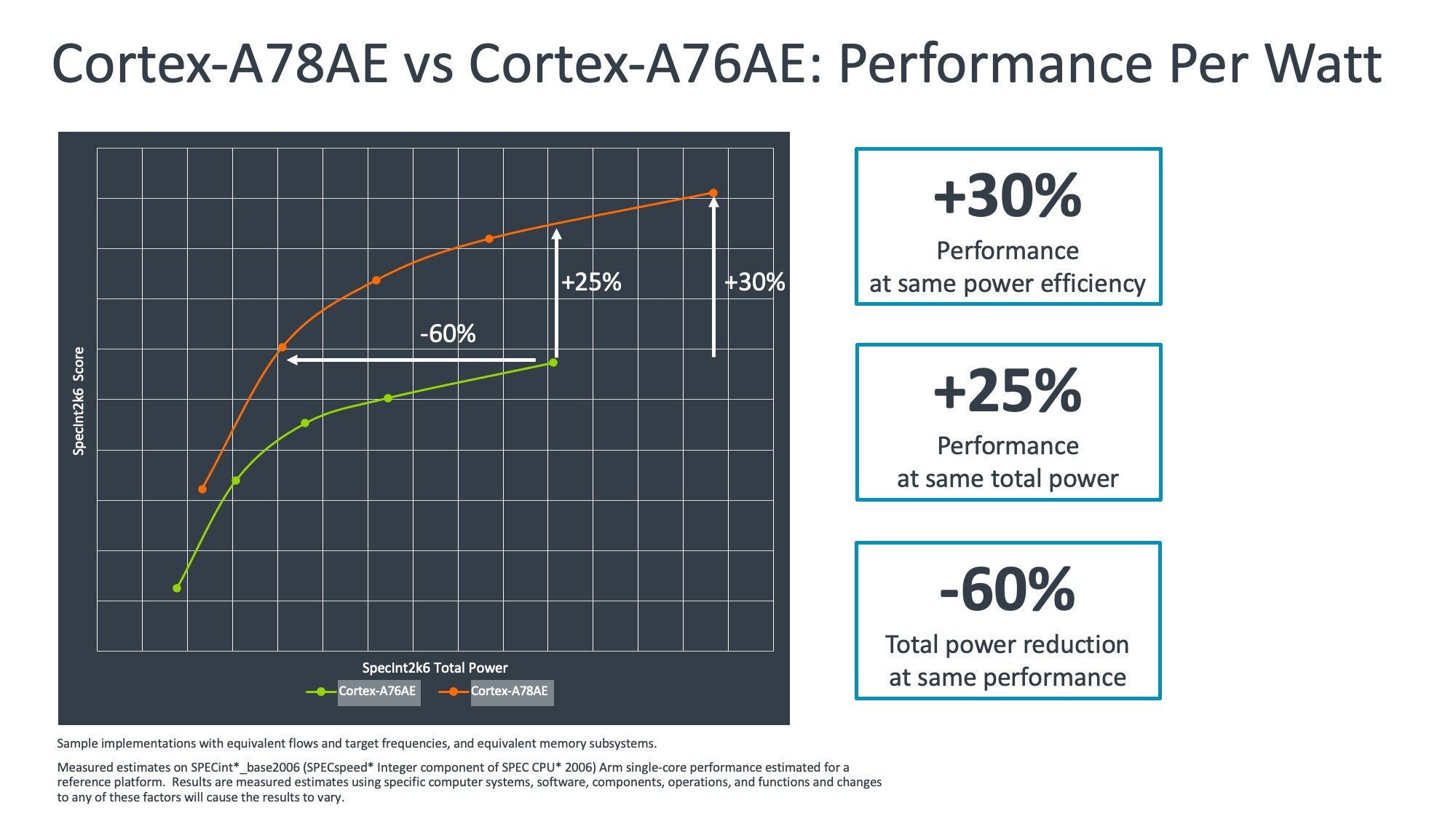 Credit: Arm The first part of the conference (October 20 to 22) also included presentations from Imagination, Ceva, Tenstorrent, Intel, Synopsys, Marvell, and Lattice. |
|
|
|||||
|
|
|||||
|
|||||




 Animation, 3D Art and 3D Models")