


EDACafe Editorial Roberto Frazzoli
Roberto Frazzoli is a contributing editor to EDACafe. His interests as a technology journalist focus on the semiconductor ecosystem in all its aspects. Roberto started covering electronics in 1987. His weekly contribution to EDACafe started in early 2019. AI chips in the spotlight at the Linley Spring Processor Conference 2020May 1st, 2020 by Roberto Frazzoli
Artificial intelligence chips continue to be the hottest topic in the processor arena – as testified by the 2020 spring edition of the Linley Processor Conference, organized by the technology analysis firm Linley Group. Due to the Covid-19 pandemic, this year the April event – usually taking place in Santa Clara, CA – was held in a virtual format, with speakers addressing a remote audience through live streaming video. Here is a quick overview of some of the presentations. AI trends and issues: larger models, binary weights, difficult porting The keynote speech from Linley Gwennap, principal analyst of the Linley Group, offered an overview of the current trends in AI architectures. The size of AI models is growing quickly to improve accuracy: as an example, in 2014 ResNet-50 had 26 million parameters, while the recent Turing NLG (Microsoft’s Natural Language Generation model) has 17 billion parameters. This obviously calls for more powerful processors, and vendors are responding with a diverse range of architectures. Most of them follow one of these two approaches: many small cores, or a few big cores. Both have advantages and disadvantages: little cores are easier to design, to replicate and scale to multiple performance/power points, while big cores require less complex interconnect and simplify compiler/software design. Recent architectural trends also include a shift from systolic arrays to convolution-optimized architectures (examples include chips from Alibaba and Kneron), and the adoption of Binary Neural Networks (BNNs), where weights can only be zero or one. This approach greatly reduces power and storage space relative to INT8 weights, still achieving a good accuracy. BNN hardware is available from Lattice and XNOR.ai (now Apple). Gwennap also provided an overview of the AI markets. Challenging Nvidia in the training applications are Cerebras, Habana (now part of Intel), Huawei and Graphcore. Competing on the inference side are a larger number of vendors including Groq, Habana with its Goya accelerator, Xilinx with Alveo, and SambaNova. Some competitors, though, have disappeared. One of the problems with AI accelerators, Gwennap pointed out, is that popular AI applications and frameworks are built on Nvidia CUDA and therefore accelerator vendors must port these applications to their chips. Most don’t offer full compatibility, thus customer applications often fail to compile at first. Bringing up a new application often requires chip vendor’s support – and even after compiling, performance may not be optimized. New AI chip announcements: Brainchip, Tenstorrent Two of the AI chip companies participating into the virtual conference took this opportunity to announce new products. Brainchip introduced its AKD1000, a low power System-on-Chip based on the Akida “event domain” neural processor. As reported in EDACafe coverage of last October Linley Fall Processor Conference, Akida is a Spiking Neural Networks processor. Besides a 20-node Akida fabric, the new SoC includes I/O interfaces, memory interfaces, spike converters, and an Arm CPU. 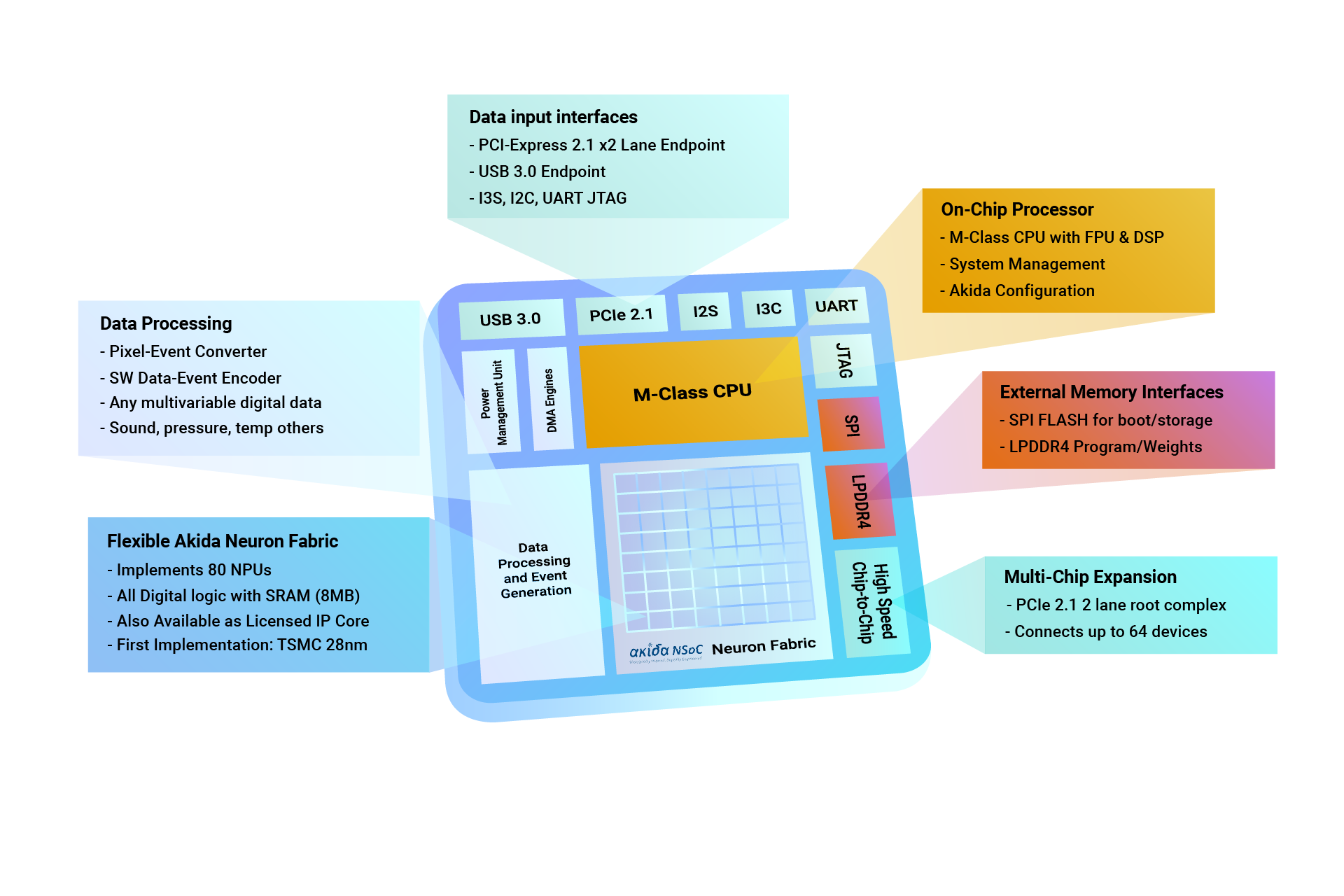 Brainchip’s AKD1000 SoC. Image credit: Brainchip Tenstorrent – a startup with offices in Toronto, Canada, and Austin, Texas – introduced a new processing architecture and its Grayskull chip. According to the company, the new architecture is flexible and scalable enough to allow convergence of training, inference and other high throughput workloads. As explained by Linley Gwennap in this issue of the Microprocessor Report, Tenstorrent is hoping to find an efficient middle ground between large monolithic architectures and arrays of tiny cores. Its 120-core chip runs at a peak rate of 368 TOPS on just 65W. To increase power efficiency, the Tenstorrent architecture takes advantage of sparsity and employs conditional execution.
Datacenter AI chips: Groq, Cerebras Groq described its Tensor Streaming Processor chip (TSP), based on the concept of “simplifying compute” to extract more performance from the available transistor budget. According to the company, general-purpose CPUs are spending their budgets on increasingly complex techniques for exposing more instruction-level parallelism. Groq’s architecture, based on “functional slicing”, disaggregates the functional units in a core and reorganizes them into “slices”. Groq claims industry leading inference performance for its TSP100 card, and a chip performance density of over 1 TeraOps per square millimeter with a 14nm process.  Groq’s Tensor Streaming Processor on a PCIe board. Image credit: PRNewsfoto/Groq Cerebras recalled the reasons behind its famous wafer-scale AI chip, a colossal 1.2 trillion transistors device. Benefits include cluster scale performance on a single chip thanks to 400,000 cores; 18 Gigabytes of fast memory, one clock cycle from core; on-chip interconnect orders of magnitude faster than off-chip; lower power and less space. Cores themselves are optimized for sparsity. Cerebras has also built a system based on its wafer-scale engine, “the world’s most powerful AI computer” according to the company. Called CS-1, it installs in standard datacenter rack and “is up and running real customer workloads at scale today.”  Cerebras’ CS-1 system. Image credit: Cerebras. More AI chips: Sima.ai, Centaur, Flex Logix Founded in early 2019, Sima.ai targets edge applications – such as cameras – that require high-performance vision processing without the high power and cost of GPU-based accelerators. The company has developed a SoC architecture that includes a ML accelerator and a standard ARM-compatible CPU. According to Linley Gwennap, who analyzed the Sima.ai approach in this white paper, the architecture of the company’s ML accelerator shifts complexity from hardware to software, thus reducing power consumption. The solution enables camera manufacturers to add machine learning without breaking their power budget. Centaur described its server processor that combines eight high performance x86 CPUs with a custom deep-learning accelerator. EDACafe briefly reported about this chip last November. Details can be found in this issue of the Microprocessor Report. Flex Logix informed the audience about a new potential application of its nnMAX architecture: DSP acceleration for functions such as FIR (finite impulse response) filters. According to the company, nnMAX is able to process up to 1 Gigasamples per second with hundreds and even thousands of “taps” or coefficients. The nnMAX architecture is the foundation of the InferX X1 AI inference co-processor that Flex Logix introduced at last October Linley conference. As explained by Mike Demler in this issue of the Linley newsletter, the key to this new application is that both neural networks and FIR filters employ massive amounts of multiply-accumulate operations. Future AI hardware: reduced precision digital processing, analog processing The keynote speech from IBM Research’s Geoffrey W. Burr focused on the research directions being pursued by IBM to dramatically increase the energy efficiency of AI hardware. Burr observed that one single model training run for an image recognition model currently requires around 400 kWh, approximately the same amount of energy used by an average household in two weeks. And the compute requirements for large AI training jobs are doubling every 3.5 months. IBM expects efficiency improvements to be delivered by “reduced precision digital processing” and, later, by analog processing. The challenge with reduced precision digital processing will be maintaining the same model accuracy. In training, this can be achieved by using specific techniques such as the “hybrid FP8” scheme, which uses two different FP8 formats for weights and activations and for gradients with loss scaling. As for inference, maintaining model accuracy can be achieved by activation quantization, weight quantization, and quantization in the presence of shortcut connections. According to IBM, the following step (from 2022 to 2025) will be the adoption of analog AI cores, which could potentially offer another 100x in energy efficiency. Among analog techniques, Burr cited the vector matrix multiplication in an analog array. Announcements from Ceva and Synopsys, updates from SiFive Besides AI chips proper, two more new product announcements concerned DSP-based processor chips and embedded processor IP. Ceva announced SensPro, described as “the industry’s first high performance sensor hub DSP architecture designed to handle the broad range of sensor processing and sensor fusion workloads for contextually-aware devices.”. Target sensors include camera, radar, LiDAR, Time-of-Flight, microphones and inertial measurement units. Built from the ground up, the SensPro architecture offers a combination of single and half precision floating-point math, along with 8- and 16-bit parallel processing capacity. SensPro incorporates Ceva-BX scalar DSP and – depending on versions – various vector units, up to a dual vector unit with 1024 8×8 MACs and binary networks support.  Image credit: Ceva Synopsys announced the new ARC HS5x (32-bit) and HS6x (64-bit) processor IP families for high-performance embedded applications. Both available in single-core and multicore versions, the two IPs are implementations of a new superscalar ARCv3 instruction set architecture and deliver up to 8750 DMIPS per core in 16-nm process technologies, making them the highest performance ARC processors to date. SiFive, from its part, provided updates on Risc-V vector extension (RVV). As highlighted by Tom R. Halfhill in this issue of the Linley Newsletter, “RVV extensions depart from the single-instruction, multiple-data (SIMD) extensions for proprietary CPUs, which fix in hardware the vector widths and numbers of elements (lanes). (…) By contrast, RVV extensions can adapt to different microarchitectures at run time.” More presentations This quick overview does not include many more presentations from other companies that participated into the 2020 virtual Linley Spring Processor Conference; let’s just briefly mention GrAI Matter Labs, Arm, Arteris, and the session devoted to “5G and AI at the Network Edge” featuring presentations from Marvell, Rambus, Mellanox etc. All slides and videos can be accessed from this page of the Linley Group website. Next event of this series, the Linley Fall Processor Conference, will be held on October 28-29, 2020 in Santa Clara, California. 2 Responses to “AI chips in the spotlight at the Linley Spring Processor Conference 2020” |
|
|
|||||
|
|
|||||
|
|||||





 Animation, 3D Art and 3D Models")
“The size of AI models is growing quickly to improve accuracy: as an example, in 2014 ResNet-50 had 26 million parameters, while the recent Turing NLG (Microsoft’s Natural Language Generation model) has 17 billion parameters” –this is really mind boggling.
Really good summary on AI chips. Looking forward to a discussion on issues of power and software eco system including the Kernel. Thanks!