Last week we briefly addressed the theme of machine learning in chip design; this week a Synopsys announcement provides a significant update on this topic. Other news includes some interesting academic research work.
Exploring design space with artificial intelligence
Synopsys has introduced DSO.ai (Design Space Optimization AI), what it claims to be the industry’s first autonomous artificial intelligence application for chip design, capable of searching for optimization targets in very large solution spaces. DSO.ai ingests large data streams generated by chip design tools and uses them to explore search spaces, observing how a design evolves over time and adjusting design choices, technology parameters, and workflows to guide the exploration process towards multi-dimensional optimization objectives. The new AI application uses machine-learning technology invented by Synopsys R&D to execute searches at massive scale: according to the company, DSO.ai autonomously operates tens-to-thousands of exploration vectors and ingests gigabytes of high-velocity design analysis data – all in real-time. At the same time, the solution automates less consequential decisions, like tuning tool settings. The announcement press release includes a quote from early-adopter Samsung, testifying that Synopsys’ DSO.ai systematically found optimal design solutions that exceeded previously power-performance-area results. Furthermore, DSO.ai was able to achieve these results in three days – as opposed as over a month of experimentation when the process is performed by a team of expert designers.
New Xilinx adaptive compute acceleration platform
Xilinx has announced Versal Premium, the third series in the Versal ACAP (adaptive compute acceleration platform) portfolio. The Versal Premium series is built on a foundation of the currently shipping Versal AI Core and Versal Prime ACAP series. New and unique to Versal Premium are 112Gbps PAM4 transceivers, multi-hundred gigabit Ethernet and Interlaken connectivity, high-speed cryptography, and PCIe Gen5 with built-in DMA, supporting both CCIX and CXL. The new platform is designed for the highest bandwidth networks operating in thermally and spatially constrained environments, as well as for cloud providers who need scalable, adaptable application acceleration.
Image credit: Xilinx
Low power audio AI applications at the edge
Cadence has optimized the software of its Tensilica HiFi DSPs to efficiently execute TensorFlow Lite for Microcontrollers, part of the TensorFlow end-to-end open-source platform for machine learning from Google. This promotes rapid development of edge applications that use artificial intelligence and machine learning,removing the need for hand-coding the neural networks. According to Cadence, Tensilica HiFi DSPs are the most widely licensed DSPs for audio, voice and AI speech; support for TensorFlow Lite for Microcontrollers enables licensees to innovate with ML applications like keyword detection, audio scene detection, noise reduction and voice recognition, with an extremely low-power footprint.
Image sensor with neural network capability
Researchers from Vienna University of Technology (Vienna, Austria) have demonstrated how an image sensor can itself constitute a neural network that can simultaneously sense and process optical images without latency. The device is based on a reconfigurable two-dimensional array of tungsten diselenide photodiodes, and the synaptic weights of the network are stored in a continuously tunable photoresponsivity matrix. In other words, the sensitivity of each photodiode can be individually adjusted by altering an applied voltage, and sensitivity factors work like weights in a neural network. By creating the appropriate sensitivity pattern, the image sensor as a whole acquires the ability to perform some basic machine learning function. The experimental device is a square array of nine pixels, with each pixel consisting of three photodiodes; resulting currents (analog signals) are summed along a row or column, according to Kirchhoff’s law. The researchers demonstrated that the device could sort an image into one of three classes that correspond to three simplified letters, and thus identify which letter it is in nanoseconds. Throughput is in the range of 20 million bins per second. Practical applications of this interesting concept would require solving a number of problems inherent to the technology used in the research chip, such as difficult imaging under dim light, high power consumption, difficult manufacturing over large areas etc. With different sensors, the same concept could be extended to other physical inputs for auditory, tactile, thermal or olfactory sensing.
Nanoelectromechanical relays have emerged as a promising alternative to transistors for creating non-volatile memories that can operate in extreme temperatures with high energy efficiency. However, until now, a reliable and scalable non-volatile relay that retains its state when powered off has not been demonstrated. Now researchers from University of Bristol, in collaboration with the University of Southampton and the Royal Institute of Technology (Sweden), have come up with a new architecture that overcomes those limitations. As the team explained, part of the challenge is the way electromechanical relays operate. When actuated, a beam anchored at one end moves under an electrostatic force; as the beam moves, the airgap between the actuation electrode and beam rapidly reduces while the capacitance increases. At a critical voltage called the pull-in voltage, the electrostatic force becomes much greater than the opposing spring force and the beam snaps in. The Bristol team explained that this inherent electromechanical pull-in instability makes precise control of the moving beam, critical for non-volatile operation, very difficult. The new device, instead, is a rotational relay that maintains a constant airgap as the beam moves, eliminating this electromechanical pull-in instability. Using this relay, the researchers have succeeded in demonstrating the first high-temperature non-volatile nanoelectromechanical relay operation, at 200 °C. Potential applications include electric vehicles as well as zero-standby power intelligent nodes for the IoT.
Image credit: Dr Dinesh Pamunuwa
Acquisitions
Ansys has entered into a definitive agreement to acquire Lumerical, a developer of photonic design and simulation tools. With optical networks becoming increasingly important in data center architectures and other applications, Lumerical’s products enable designers to model problems in photonics, including interacting optical, electrical and thermal effects. Infineon Technologies will proceed to acquireCypress Semiconductor; the Committee on Foreign Investment in the United States (CFIUS) has concluded its review of the planned acquisition and cleared the transaction. TE Connectivity, a provider of connectivity and sensing solutions, completed its public takeover of First Sensor, a German player in sensor technology. TE now holds 71.87% shares of First Sensor. Silicon Labs has entered into a definitive agreement with Redpine Signals to acquire the company’s Wi-Fi and Bluetooth business, development center in Hyderabad, India, and patent portfolio for $308 million in cash. The integration of the Redpine Signals technology is expected to accelerate Silicon Labs’ roadmap for Wi-Fi 6 silicon, software and solutions.
The growing role of neural networks in chip design has been a recurring theme over the past few weeks, in speeches or announcements involving a number of different subjects. Meanwhile, the new golden age of innovative processing architectures continues, spurred by 5G requirements. Other recent news includes more EDA vendors end-of-year results, and acquisitions in the semiconductors industry.
Machine learning to improve place-and-route in chip design
Better placement and routing in much less time and, ultimately, a dramatic reduction of ASIC design time: this is what machine learning promises to the chip designer community. ML-powered place-and-route was one of the key points of Google’s Jeffrey Dean keynote speech at the recent ISSCC. In a paper packed of interesting insights and data about machine learning evolution, Dean addressed this issue with concepts that are bound to raise attention. According to Dean, “placement and routing is a problem that is amenable to the sorts of reinforcement learning approaches that were successful in solving games, like AlphaGo. (…) By having a reinforcement learning algorithm learn to ‘play’ the game of placement and routing (…), with a reward function that combines the various attributes into a single numerical reward function, and by applying significant amounts of machine-learning computation (in the form of ML accelerators), it may be possible to have a system that can do placement and routing more rapidly and more effectively than a team of human experts working with existing electronic design tools for placement and routing”, Dean maintains. Google has been exploring these approaches internally, obtaining promising results; some of them have been described in this EETimes article. In his paper, Dean cites more potential benefits that chip design could get from machine learning: “The automated ML based system also enables rapid design space exploration, as the reward function can be easily adjusted to optimize for different trade-offs in target optimization metrics. Furthermore – he continues – it may even be possible to train a machine learning system to make a whole series of decisions from high-level synthesis down to actual low-level logic representations (…)”. According to Dean, this automated end-to-end flow could potentially reduce the time for a complex ASIC design from many months down to weeks, thus allowing the development of custom chips for a much larger range of applications.
Major EDA vendors have already started adding machine learning capabilities to their product portfolio. Among them Synopsys, whose IC Compiler II place-and-route solution – part of the Synopsys Fusion Design Platform – includes machine learning technologies. Samsung has recently adopted Synopsys’ IC Compiler II place-and-route solution for its 5nm mobile system-on-chip production design, reporting – thanks to machine learning – up to five percent higher frequency, five percent lower leakage power and faster turn-around-time.
And Samsung’s Joydip Das, Senior Engineer at the company’s Austin R&D center, is chairing the new special interest group launched by Silicon Integration Initiative (Si2) to focus on the growing needs and opportunities in artificial intelligence and machine learning for electronic design automation. Other Si2 members participating in the SIG include Advanced Micro Devices, Ansys, Cadence, Hewlett Packard Enterprise, IBM, Intel, Intento Design, NC State University, PDF Solutions, Sandia Labs, Synopsys and the University of California, Berkeley.
Ceva unveils a superfast DSP
Ceva has recently announced what it claims to be “the world’s most powerful DSP architecture”, the Gen4 CEVA-XC, targeted at the most complex parallel processing workloads required for 5G endpoints and Radio Access Networks, enterprise access points and other multigigabit low latency applications. As stated in a company’s press release, the Gen4 CEVA-XC unifies the principles of scalar and vector processing enabling two-times 8-way VLIW and up to 14,000 bits of data level parallelism. The devices incorporate a pipeline architecture enabling operating speeds of 1.8 GHz at a 7nm process node using a unique physical design architecture for a fully synthesizable design flow, and an innovative multithreading design. This allows the processors to be dynamically reconfigured as either a wide SIMD machine or divided into smaller simultaneous SIMD threads. The first processor based on the Gen4 CEVA-XC architecture is the multicore CEVA-XC16, described by the company as “the fastest DSP ever made”. Architected with the latest 3GPP release specifications in mind, the CEVA-XC16 offers up to 1,600 Giga Operations Per Second that can be reconfigured as two separate parallel threads. According to Ceva, new concepts used in this device boost the performance per square millimeter when massive numbers of users are connected in a crowded area, leading to 35% die area savings for a large cluster of cores, as is typical for custom 5G base station silicon.
CEVA-XC16 block diagram. Image credit: CEVA
Ansys results
Ansys has recently reported fourth quarter 2019 GAAP and non-GAAP revenue growth of 17% and 18%, respectively, or 18% for each in constant currency. For fiscal year 2019, GAAP and non-GAAP revenue growth was 17%, or 19% in constant currency. In a press release, Ansys President & CEO Ajei Gopal stated that in 2019 the company extended its market and technology leadership and differentiated its multiphysics product portfolio both organically, as well as through strategic acquisitions, and expanded its partner ecosystem. “Our vision of making simulation pervasive across the product lifecycle is resonating with customers and partners”, he said.
Ansys has also expanded its product portfolio with the recent release of RaptorH, targeted at accelerating and improving 5G, three-dimensional integrated circuit and radio-frequency integrated circuit design workflows. RaptorH fuses features from two preexisting Ansys products: HFSS and RaptorX.
Recent acquisitions
UK-based Dialog Semiconductor – a provider of power management, charging, AC/DC power conversion, Wi-Fi and Bluetooth low energy technology – has announced the acquisition of Adesto Technologies. Based in Santa Clara, CA, Adesto is a provider of custom integrated circuits and embedded systems for the Industrial Internet of Things market. Mellanox Technologies, a supplier of interconnect solutions for data center servers and storage systems, has announced that it will acquire Titan IC, a developer of network intelligence and security technology. STMicroelectronics has signed an agreement to acquire a majority stake in Gallium Nitride specialist Exagan. Founded in 2014 and headquartered in Grenoble, France, Exagan is dedicated to accelerating the power-electronics industry’s transition from silicon-based technology to GaN-on-silicon technology, enabling smaller and more efficient electrical converters.
Chips designed in Silicon Valley power the ICT industry around the world, enabling big corporations and startups alike to deliver innovative products and services. Some of these startups are on their way to become “unicorns”, companies that will eventually be valued at $1B or more. An interesting point is finding out which of these future unicorns will find their grazing prairies in Silicon Valley or in other spots within the San Francisco Bay Area, thus enriching the same tech-intensive and capital-intensive environment where many enabling semiconductor technologies come from. Let’s take a quick look at twenty-two of these Bay Area startups, with the help of a list compiled by market research firm CB Insights in collaboration with The New York Times. The original full list includes fifty companies around the world, and a first significant data is that the Bay Area alone makes up almost half of this group of thriving startups.
Fintech
Fintech (financial technology) is the largest category here, with five companies. Blend (San Francisco) is a digital lending platform for mortgages and consumer banking. Carta (San Francisco) helps companies and investors manage equity and ownership, on aspects such as cap tables, valuations, portfolio investments, and equity plans. Earnin (Palo Alto) is a community-supported platform mostly targeted at helping people with services such as protection from bank overdrafts, cash back rewards, immediate access to weekly or monthly salary, negotiation of medical bills. Marqeta(Oakland) offers an open API for payment card issuing, that can be used by companies to build their own payment solutions. Upgrade (San Francisco) is an online lending platform that combines personal loans with free credit monitoring.
IoT edge devices take center stage this week with two significant announcements concerning low power neural processors and a UCSD research work on low power Wi-Fi, the latter presented at the recent ISSCC. Another research from UCSD promises advances in Lithium batteries; and another ISSCC paper describes a new active interposer technology boosting the capabilities of chiplet-based devices.
Arm’s Neural Processing Unit
Arm has recently announced the Ethos-U55, a microNPU (Neural Processing Unit) for Cortex-M, claiming a combined 480x leap in machine learning performance. The new solution targets small, power-constrained IoT and embedded devices. Ethos-U55 key features include the possibility of choosing multiple configurations to target different AI applications; an area of just 0.1mm2 to reduce energy consumption for ML workloads up to 90% compared to previous Cortex-M generations; a unified toolchain (for both Ethos-U55 and Cortex-M); native support for the most common ML network operations including CNN and RNN. Heavy compute operators – such as convolution, LSTM, RNN, pooling, activation functions, and primitive element wise functions – run directly on the Ethos-U55, while other kernels run automatically on the tightly coupled Cortex-M using CMSIS-NN. Several innovations contribute to the dramatic performance increase provided by Ethos-U55. Utilization of MAC engines on popular networks reaches 85%; operator and layer fusion, as well as layer reordering, increase performance and reduce system memory requirements up to 90%; weights and activations are fetched ahead of time using a DMA connected to system memory via AXI5 master interface; the use of an advanced, lossless model compression reduces model size up to 75% etc. Arm partners that have announced support for the new solution include Alif Semiconductor, Au-Zone, Bestechnic, Cypress, Dolby, Google, NXP, Qeexo, Shoreline IoT, and STMicroelectronics.
Eta Compute’s Neural Sensor Processor
Eta Compute has started shipping its ECM3532, an AI multicore processor for embedded sensor applications. Targeted at always-on image and sensor applications at the edge, the ECM3532 contains an Arm Cortex-M3 processor and a DSP for machine learning acceleration. Both cores feature the company’s patented Continuous Voltage Frequency Scaling (CVFS) technique with near threshold voltage operation, to reduce active power consumption down to hundreds of microwatts. The device includes on-chip power management which simplifies the use of CVFS with high-efficiency buck (step-down) converters that generate the required internal voltages. With the ECM3532, Eta Compute is mostly targeting applications such as sound classification, keyword spotting, object detection, people detection, people counting, activity classification, context awareness, defect detection and others. Audio AI applications can take advantage of the chip’s multiple methods of acquiring audio samples – from digital and analog MEMS microphones.
Connecting IoT devices to Wi-Fi with a 28 microwatts power budget
Using a technique called backscattering, an IoT device can take incoming Wi-Fi signals from a nearby device (like a smartphone) or Wi-Fi access point, modify those signals to encode its own data onto them, and then reflect the new signals onto a different Wi-Fi channel to another device or access point. In this way, the IoT device can communicate with existing Wi-Fi networks consuming just 28 microwatts. The innovation comes from the University of California San Diego and has been presented at the recent ISSCC 2020 conference in San Francisco. Transmission data rate is 2 megabits per second over a range of up to 21 meters. Thanks to a wake-up receiver, the solution can spend part of the time in sleep mode absorbing only 3 microwatts.
How backscattering works. Image credit: UCSD
Active interposer enables better chiplet-based devices
Also presented at the ISSCC 2020, a work from French research institute CEA-Leti concerning a 96-core processor that consists of six chiplets placed on top of an active interposer. According to the researchers, conventional large-scale interposer techniques for chiplet integration – such as 2.5D passive interposers, organic substrates, and silicon bridges – have shortcomings on many aspects: long-distance chiplet-to-chiplet communications, integration of heterogeneous chiplets, integration of functions such as power management, analog IP and I/O IP. The active interposer developed by CEA-Leti, instead, integrates voltage regulators, flexible system interconnect topologies between all chiplets, energy-efficient 3D-plugs for dense high-throughput, inter-layer communication, and a memory-IO controller and the physical layer (PHY) for socket communication. The six chiplets – built in 28nm FDSOI CMOS node – are 3D-stacked in a face-to-face configuration using 20µm pitch micro-bumps onto the active interposer embedding through-silicon vias (TSVs) in a 65nm technology node. The device has been designed with a Mentor Graphics 3D CAD tool flow and implemented on a STMicroelectronics process.
Image credit: CEA-Leti
Ultrasound prevents “dendrites” in lithium metal batteries
Lithium metal batteries have twice the capacity of today’s best lithium ion batteries but their lifespan is too short due to the development of needle-like structures called dendrites, that can grow unchecked from the anode towards the cathode causing the battery to short circuit and even catch fire. Researchers from the University of California San Diego have come up with a solution that prevents the development of dendrites: an ultrasound device integrated in the battery, propagating waves that cause the liquid electrolyte to flow – instead of standing still. The ultrasound device is made from off-the-shelf smartphone components and can be used in any battery, including commercial lithium ion batteries, to shorten charging time.
The ultrasound device that prevents dendrites in batteries. Image credit: UCSD
Automotive FuSa solutions
Samsung Foundry has successfully deployed the Synopsys TestMAX XLBIST solution on an automotive integrated circuit to provide dynamic in-system testing for critical failures, in order to meet stringent automotive functional safety (FuSa) requirements concerning automotive safety integrity levels (ASILs) for autonomous driving and advanced driver-assistance systems (ADAS). Using TestMAX XLBIST, Samsung was able to implement dynamic in-system test, which periodically executes during key phases of vehicle operation, including power-on, drive mode, and power-off. Functional safety is also being addressed by Accellera, that has recently announced the formation of a specific Working Group to create a standard that improves interoperability and traceability in the functional safety lifecycle.
Upcoming events
Cancellation of the Mobile World Congress in Barcelona is probably the biggest consequence of the Covid-19 outbreak on tech events so far. Fortunately, other important tech shows are confirmed: as we write (February 21), the Embedded World Conference website says that the event “takes place as planned”, from February 25 to 27. However, some important exhibitors have withdrawn from the Nuremberg, Germany, show. For live updates on the Covid-19 impact on the electronics industry, readers can check this EE Times Europe page. Other IT events planned for next week include the RSA Conference 2020, February 24 to 28 in San Francisco.
End of year earnings calls continue; this week it’s Cadence’s turn, with Lip-Bu Tan sharing some details about 2019 customers. More news from the last few weeks include some announcements concerning memories, with the addition of updates on neural networks applications and startups developing new processors.
Cadence 2019 results
Cadence reported 2019 revenue of $2.336 billion, compared to revenue of $2.138 billion for 2018. On a GAAP basis, the company achieved an operating margin of 21 percent and a net income of $989 million in 2019, compared to operating margin of 19 percent and net income of $346 million for 2018. As for 2020, Cadence expects total revenue in the range of $2.545 billion to $2.585 billion. On a GAAP basis, operating margin is expected to be 21 to 22 percent. During the financial results conference call, Cadence’s CEO Lip-Bu Tan summarized the company’s major achievements for 2019: among them, about 50 new full-flow wins, including one for new advanced node designs with “a leading maker of FPGA chips”; he also mentioned successes in the digital business – with customers such as MediaTek, Samsung, Socionext, Innovium, Mellanox, Uhnder – and a win for the Xcelium parallel simulator at “a leading U.S. computing company”. Cadence IP royalty growth was strong particularly in the audio market, where Tensilica HiFi DSP processors are increasingly being adopted in True Wireless Stereo based earbuds, and in the next generation of smart speakers. In 2019 Cadence entered the System Analysis market introducing the Clarity 3D Solver and the Celsius Thermal Solver, solutions targeted at electromagnetic field simulation and electro-thermal co-simulation respectively; Lip-Bu Tan said that Cadence is “extremely pleased” with the ramp of these innovative products, with well over 90 evaluations underway and more than 20 customers to date, including Micron, STMicro, Kioxia, Realtek, and Ambarella.
Lip-Bu Tan. Image credit: Cadence
Memory updates: Flash, LP DRAM, ReRAM
A quick roundup of some recent memory updates. Kioxia Europe (formerly Toshiba Memory Europe) has successfully developed its fifth generation BiCS Flash three-dimensional flash memory with a 112-layer vertically stacked structure. The new device has a 512 gigabit (64 gigabytes) capacity with 3-bit-per-cell (triple-level cell) technology. Kioxia plans to start shipping samples for specific applications in the first quarter of this year. Micron Technology has delivered what it claims is the world’s first low-power DDR5 DRAM in mass production, to be used in the soon-to-be-released Xiaomi Mi 10 smartphone. The company is shipping LPDDR5 to customers in capacities of 6GB, 8GB and 12GB and at data speeds of 5.5Gbps and 6.4Gbps. Weebit Nano has launched a program to address the needs of discrete memory components based on its ReRAM memory technology. This broadens the work program for Weebit beyond just the “embedded” non-volatile memory market. According to Weebit, discrete memory chips contain larger memory arrays and are more technically challenging than embedded modules, requiring additional development work before reaching productisation. A key element required for discrete memory chips is called a “selector”, which helps to selectively modify specific cells – while the others are not impacted. The work required for the discrete memory chips will be performed by Weebit in co-operation with French research institute Leti.
The new Kioxia BiCS Flash. Image credit: Kioxia
Neural networks-based video compression
Artificial intelligence is gaining traction in image and video compression. Among the machine learning capabilities that Xilinx is offering to professional audio-video market customers, the ‘Region-of-Interest Encoding’ detects faces and features in the video image so that the H.264/H.265 codec integrated in the Zynq UltraScale+ MPSoC can keep video quality high in those areas, and apply a higher compression for backgrounds. But besides distinguishing faces from background, neural networks can be used for compression itself – and Google has announced the new edition of a workshop specifically devoted to this new application. As noted in a Google AI Blog post, in 2015 researchers demonstrated that neural network-based image compression could yield significant improvements to image resolution while retaining good quality and high compression speed. The Third Workshop and Challenge on Learned Image Compression (CLIC) will be held at the CVPR 2020 conference. Researchers will be challenged to use machine learning, neural networks and other computer vision approaches to increase the quality and lower the bandwidth needed for multimedia transmission. This year’s workshop will include a low-rate image compression challenge (squeezing an image dataset to 0.15 bits per pixel) and a P-Frame video compression challenge.
New server processors promising a tenfold efficiency boost
Back in October 2018, the Microprocessor Report analyzed Tachyum’s Prodigy server processor and concluded: “If [Tachyum] can stick to its plan and deliver compelling performance, hyperscale companies will strongly consider [Prodigy] as an alternative to Intel’s Xeon”. Tachyum – a Silicon Valley based semiconductor startup, with R&D development center in Bratislava, Slovakia – has recently taken a new step towards real-world applications: its Prodigy Processor AI/HPC Reference Design will be used in a supercomputer which will be deployed in 2021. True to its name, the new chip promises prodigious performance: as stated in a Tachyum press release, “in normal datacenter workloads, Prodigy handily outperforms the fastest processors while consuming one-tenth the electrical power, and it is one-third the cost. In AI applications, Prodigy outperforms GPUs and TPUs on neural net training and inference workloads, and is orders of magnitude easier to program”. Prodigy, a 64-core processor with a clock speed in excess of 4GHz, is slated for commercial availability in 2021.
Another company aiming to reduce power consumption in datacenters is Triple-1 (Fukuoka, Japan), that has announced the development of an AI processor called Goku which will be fabricated in a 5-nanometer process. As of today, little details are available in the company’s website. Triple-1 is mostly stressing the power efficiency benefits of using a 5-nanometer process and a manually optimized design. According to Triple-1, there are currently no mass-produced AI chips fabricated in a process geometry smaller than 12-nanometer. Goku, too, promises a tenfold improvement in power efficiency, reaching 10 TFLOPS/W. Expected peak performance (half-precision) is 1 PFLOPS (1,000 TFLOPS). Mass production of Goku is scheduled for 2021.
Despite declines, 2019 was Silicon Valley’s second biggest year for investments – according to the recent MoneyTree report (Q4 2019) mainly focused on US investments, jointly released by PricewaterhouseCoopers and CB Insights. Companies based in Silicon Valley or in San Francisco received $47.2 billion in 1,722 deals last year, down from a record $61.0 billion and 1,987 deals in 2018. These figures only include equity financings into VC-backed private companies, which are defined by the report as companies that have received funding at any point from venture capital firms, corporate venture arms, or super angel investors. The Bay Area continues to absorb a large slice of tech investments, but the twenty-seven Silicon Valley-based or San Francisco-based companies that occupy top places in the report’s investment rankings – in categories such as the most valuable US unicorns, largest US deals, top IPOs, top funded companies, top mega-rounds etc. – are not directly related with chipmaking. Some of these companies are big and famous, other are probably not so well known outside their specific markets. Let’s take a quick look at them.
FinTech, real estate tech and more money-related platforms
FinTech (financial technology) and related online services is one of the areas where companies based in the Bay Area took center stage in 2019: among them Bill.com (Palo Alto), Ripple (San Francisco) and Stripe (San Francisco), three different types of online payment platforms. Also in the FinTech group are Chime (San Francisco), that can be described as an Internet banking company, and SoFi (San Francisco), an online loan platform. Real estate tech is another hot industry in the Bay Area; companies in the spotlight include Figure Technologies, HomeLight, Juniper Square, Qualia and Zeus, all based in San Francisco. Figure Technologies offers an online platform for home equity line of credit; HomeLight enables users to choose the best real estate agents in their areas; Juniper Square provides real estate investment management software; Qualia is an online platform for ‘real estate closing’; Zeus is a home rental platform. Also linked to real estate, of course, is Airbnb (San Francisco). To complete the category of money-related services, InsureTech (insurance technology) is another lively area with companies such as Next Insurance (Palo Alto), specializing in online insurances for small businesses.
Digital health, autonomous vehicles and other products
A completely different tech-based industry is digital health, where prominent Bay Area companies cited by the MoneyTree report Q4 2019 include ArsenalBio, GenapSys, Grail and Vir Biotechnology. Let’s take a quick look at them: ArsenalBio (South San Francisco) works on immune cell therapies; GenapSys (Redwood City) manufactures DNA sequencing equipment; Grail (Menlo Park) works on early cancer detection; Vir Biotechnology (San Francisco) is in the business of preventing serious infectious diseases. Moving to industries more closely related to computing, attracting investments in 2019 were Databricks (San Francisco) and Palantir (Palo Alto), active in data analytics and data management respectively; also cited in the report are cybersecurity company Shape Security (Santa Clara), recently acquired by Seattle-based F5; robotic process automation company Automation Anywhere (San Jose); and of course OpenAI (San Francisco). Autonomous vehicles obviously attracted investments in 2019, too, with companies such as Cruise (San Francisco), Nuro (Mountain View), specializing in delivery vehicles, and Zoox (Foster City). Completing the picture, three San Francisco-based companies from various industries: Flexport, an online platform for freight forwarding; Juul Labs, making electronic cigarettes; and Dolls Kill, an apparel e-commerce platform.
Cruise Origin. Image credit: Cruise
Another research from CB Insights, in association with The New York Times, has identified fifty future ‘unicorns’, that is, high-momentum startups likely to be eventually valued at $1B or more. The list obviously includes companies based in the San Francisco bay area, and EDACafe is planning to provide more details about them in the upcoming weeks.
Venture capital: Sand Hill Road still a hot spot
Bay Area venture capital firms played a key role in 2019 – considering all investment geographies, not just Silicon Valley tech companies. According to the MoneyTree report, Sequoia Capital and Andreessen Horowitz, both based in Menlo Park, ranked first and second with $7.4 billion and $6.5 billion of fund raised respectively. A third firm based in Menlo Park, New Enterprise Associates, leads the group of the most active VCs in 2019 with 87 deals. This ranking includes three more Bay Area VCs: Plug and Play Ventures (Sunnyvale), Founders Fund (San Francisco) and Google Ventures (Mountain View). Two more firms must be mentioned among the most active VCs when considering Q4 2019 deals alone: Accel (Palo Alto) and Lightspeed Venture Partners (Menlo Park). Famous Sand Hill Road, where most of the Menlo Park-based VCs are located, is still a hot spot for tech investments.
Upcoming events
Back to silicon, now, with some info on upcoming events. ISSCC (International Solid-State Circuits Conference) will take place from February 16th to 20th in San Francisco, while the Mobile World Congress (MWC) is scheduled for February 24th to 27th in Barcelona, Spain. Same week, February 25th to 27th, for the Embedded World show in Nuremberg, Germany. Next month – March 9th to 13th – the French city of Grenoble will host the DATE Conference; same week for the AI Hardware Summit Europe, taking place in Munich, Germany, on March 10th and 11th. Unfortunately, attendance to some of the events taking place over the next few weeks will probably be impacted by the Coronavirus fear and related air travel restrictions.
On one side, a plethora of difficult technological hurdles – such as the ones that will be addressed by the upcoming SPIE conference on advanced lithography. On the other side, major companies developing or using EUV systems – such as ASML and TSMC – confidently expecting that all those hurdles will be overcome. The current status of EUV lithography can probably be considered as a good example of the unshakeable trust in technological progress that has always driven the semiconductor industry. And evidence shows that this trust is well placed: 7-nanometer chips manufactured with EUV lithography are now in volume production. January 2020 earnings conferences from both ASML and TSMC offered some interesting insights on what the industry is expecting from EUV lithography, and the program of the above-mentioned SPIE conference speaks volumes about the challenges implied in those expectations. (more…)
Equipment, materials and processes are in the spotlight this week – but innovative algorithms and architectures deserve their share of attention, too.
Strong EUV demand drives ASML growth
Several years in the making, EUV lithography is now paying off for ASML. Fourth-quarter and full-year results just announced by the Dutch equipment manufacturer look very good: Q4 2019 net sales totaled €4.0 billion, with net income of €1.1 billion and gross margin of 48.1%. As for full 2019 results, net sales amounted to €11.8 billion with net income of €2.6 billion. For the first quarter of 2020, ASML expects net sales of between €3.1 billion and €3.3 billion and a gross margin between 46% and 47%. “We shipped eight EUV systems in the fourth quarter and we received orders for nine EUV systems,” said ASML’s CEO Peter Wennink in a statement. “We expect that 2020 will be another growth year, both in sales and in profitability, driven by EUV demand and our Installed Base business. The Logic market is expected to remain strong in 2020, due to investments in 5G and high-performance compute applications. In the Memory market, our customers are starting to see the first signs of recovery,” Wennink added. (more…)
Last week and in late December we focused on the unified programming platforms recently introduced by Xilinx and Intel respectively. This week we try to catch up on some of the major news from the last thirty days or so. Let’s start by briefly mentioning that Facebook is reportedly planning to develop its own operating system. And now, more updates from industry and research.
No driver – and no lidar, too
CES, of course, was the biggest IT-related event of this new year’s start, and autonomous driving was obviously a major theme in Las Vegas. One of the hurdles delaying this technology is the high number and cost of sensors, such as lidars. But that could change soon: at CES 2020, Mobileye President and CEO Prof. Amnon Shashua discussed ‘Vidar’, Mobileye’s solution for achieving outputs akin to lidar using only camera sensors. He showed a 23-minute video of an autonomous vehicle navigating with camera-only sensors in a complex environment. Also focusing on enhancing camera performance for autonomous driving is the collaboration between ON Semiconductor and Pony.ai – the first company to roll out daily robotaxi operation in China and in California. (more…)
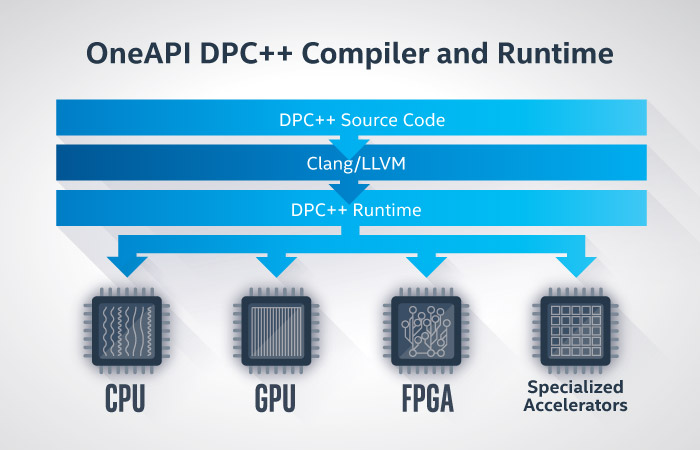
Last November Intel introduced oneAPI, described as “a single, unified programming model that aims to simplify development across multiple architectures – such as CPUs, GPUs, FPGAs and accelerators”. This week we take a closer look at oneAPI with the help of Herb Hinstorff, Director of Marketing, Software Developer Products Division at Intel.
Image credit: Intel
Before proceeding to our Q&A session, let’s briefly summarize what oneAPI is about. As described in the Intel’s fact sheet, there are two components of oneAPI: an industry initiative and the Intel beta product. The oneAPI initiative cross-architecture development model is based on industry standards and an open specification, to enable broad ecosystem adoption. The Intel oneAPI beta product is Intel’s implementation of oneAPI that contains the oneAPI specification components with direct programming (Data Parallel C++), API-based programming with a set of performance libraries, advanced analysis and debug tools, and other components. Developers can test their code and workloads in the Intel DevCloud for oneAPI on multiple types of Intel architectures today, including Intel Xeon Scalable processors, Intel Core processors with integrated graphics and Intel FPGAs (Arria, Stratix). The development flow devised for FPGAs – a target traditionally requiring Verilog or VHDL skills, as reminded by Kevin Morris’ article on EEJournal – is described in the following diagram. (more…)




















 Animation, 3D Art and 3D Models")