


EDACafe Editorial Roberto Frazzoli
Roberto Frazzoli is a contributing editor to EDACafe. His interests as a technology journalist focus on the semiconductor ecosystem in all its aspects. Roberto started covering electronics in 1987. His weekly contribution to EDACafe started in early 2019. Nvidia-powered CAE acceleration; new Keysight EDA software; CoWoS roadmap; new datacenter inference solutionNovember 20th, 2024 by Roberto Frazzoli
Artificial intelligence is the common underlying theme in most of the news this week. But first, some CHIPS Act updates. Biden-Harris administration to finalize some subsidies Some of the last moves from the Biden-Harris administration include finalizing part of the planned subsidies to support the U.S. semiconductor industry. TSMC Arizona has been awarded up to $6.6 billion to support the company’s planned investment of more than $65 billion in three greenfield leading-edge fabs in Phoenix, Arizona. GlobalFoundries has been awarded up to $1.5 billion to support the expansion of its existing fab in Malta, New York, the upgrading of its existing fab in Essex Junction, Vermont, and the construction of a new fab in Malta, New York. In addition to that, Akash Systems (Oakland, CA) has signed a non-binding preliminary memorandum of terms with the U.S. Department of Commerce under the CHIPS and Science Act to receive over $68 million in direct funding to support the operational ramp-up of its Diamond Cooling semiconductor technologies. Nvidia accelerates CAE digital twins Nvidia has announced an Omniverse Blueprint that enables industry software developers to help their CAE customers create digital twins with real-time interactivity. Software developers such as Altair, Ansys, Cadence and Siemens can use the Nvidia Omniverse Blueprint, a reference workflow that includes Nvidia acceleration libraries, physics-AI frameworks and interactive physically based rendering to achieve – according to the company – 1,200x faster simulations and real-time visualization. One of the first applications of the blueprint is computational fluid dynamics simulations. Ansys ran Fluent at the Texas Advanced Computing Center on 320 Nvidia GH200 Grace Hopper Superchips. A 2.5-billion-cell automotive simulation was completed in just over six hours, which would have taken nearly a month running on 2,048 x86 CPU cores.
Ansys integrates the Nvidia Modulus AI framework Ansys is also integrating the Nvidia Modulus AI framework into its semiconductor simulation products to create customized and generative AI surrogate models that accelerate design iterations and explore a larger design space. Nvidia Modulus is a physics-AI framework to train and deploy models that combine physics-based domain knowledge with simulation data. For example, designers can train their AI models in the integrated Modulus framework using their library of completed designs in Ansys RedHawk-SC. Once the AI is trained, it can be used to identify optimal designs based on desired specifications — such as size, power, and performance — in a fraction of the time. Ansys plans to add Modulus-created AI accelerators to its semiconductor solutions including RedHawk-SC, Totem-SC, PathFinder-SC, and RedHawk-SC Electrothermal. New Keysight EDA software leverages artificial intelligence Keysight’s EDA 2025 software includes several new features. As for RF circuit design, the suite enables design acceleration through automatable workflows featuring Python integration and multi-domain simulation. Additionally, the Python toolkit enables to consolidate measured load pull data from various files and formats into a single dataset to train AI/ML models. As for high-speed digital design, the software creates digital twins for complex standard-specific SerDes designs, including UCIe chiplets, memory, USB, and PCIe. Lastly, device modeling and characterization can benefit from a reduction of model re-centering time through AI/ML, while Python integrations streamline and automate the modeling process. TSMC’s Open Innovation Platform Ecosystem Forum EDA and advanced packaging were in the spotlight at the European edition of TSMC’s Open Innovation Platform Ecosystem Forum, recently held in Amsterdam, the Netherlands. The Taiwanese foundry cited EDA partners’ “brand-new P&R algorithms” as an enabling factor to achieve better PPA results through design-technology-cooptimization for its latest solutions, such as N3 FinFLEX, N2 NanoFLEX and A16 Super Power Rail (TSMC’s backside power delivery architecture). New EDA tools will also be instrumental in addressing the new thermal and mechanical challenges posed by 3D package scaling. As for this topic, TSMC showed an updated roadmap for its CoWoS technology, and the 3Dblox committee announced its plans to standardize 3Dblox through IEEE. Key advancements of the latest 3Dblox standard include AI-powered global resource optimization; multi-physics analysis convergence; early floorplan Design Rule Check (for rotation, flip, and projection of chiplets); auto alignment marks insertion; common constraints for early chip-package co-design. 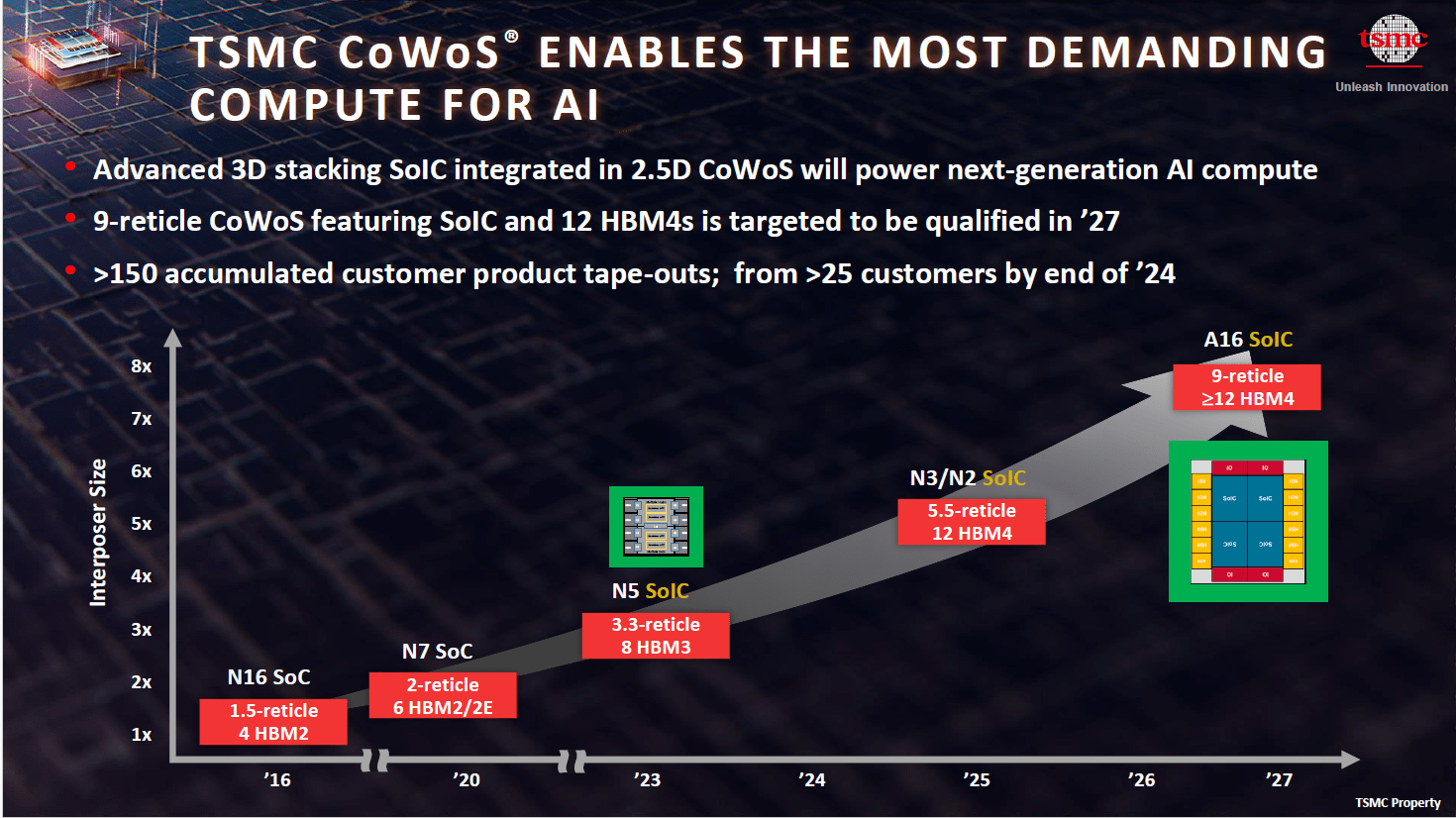 Credit: TSMC AMD-powered supercomputer achieves top spot in the latest TOP500 ranking Supercomputer “El Capitan” at the Lawrence Livermore National Laboratory in California has achieved the top spot in the 64th edition of the TOP500 ranking, and is officially the third system to reach exascale computing. The new El Capitan system has debuted with an HPL score of 1.742 EFlop/s. It has 11,039,616 combined CPU and GPU cores and is based on AMD 4th generation EPYC processors with 24 cores at 1.8GHz and AMD Instinct MI300A accelerators. El Capitan relies on a Cray Slingshot 11 network for data transfer and achieves an energy efficiency of 58.89 Gigaflops/watt. Advancements in AI competitiveness come at a price: citing the need to direct its efforts towards developing AI chips, AMD is reportedly planning to lay off 4% of its global workforce, or about 1,000 employees. New inference solution for datacenters from d-Matrix Challenging GPUs and other alternatives, Santa Clara-based d-Matrix has unveiled Corsair, what it claims is the world’s most efficient AI computing platform for inference in datacenters. According to the company, Corsair enables 60,000 tokens/second at 1 ms/token for Llama3 8B in a single server and 30,000 tokens/second at 2 ms/token for Llama3 70B in a single rack. The solution leverages d-Matrix’s “Digital In-Memory Compute” architecture and several innovations in silicon, software, chiplet packaging and interconnect fabrics. Among other features, d-Matrix natively supports block floating point numerical formats, now an OCP standard called Micro-scaling (MX). Enfabrica’s Accelerated Compute Fabric On the other hand, Enfabrica strives to improve the performance of GPU compute networks. The company has announced availability in Q1 2025 of its 3.2 Terabit/sec Accelerated Compute Fabric SuperNIC chip and pilot systems. According to the company, Enfabrica’s ACF solution delivers multi-port 800-Gigabit-Ethernet connectivity to GPU servers, and four times the bandwidth and multipath resiliency of any other GPU-attached network interface controller (NIC) product in the industry. Acquisitions Molex, a connectivity and electronics solutions provider, has signed an agreement to purchase AirBorn (Georgetown, TX), a company specializing in the design and manufacturing of rugged connectors and electronic components for OEMs serving the aerospace, defense, medical and industrial markets. |
|
|
|||||
|
|
|||||
|
|||||




 Animation, 3D Art and 3D Models")