Artificial intelligence is the common underlying theme for most of this week’s updates. Among them, Nvidia is in the news with an EDA research work, after last week announcement concerning its solution for computational lithography – the last software step before mask production.
Nvidia research on AI-based macro placement
At the recent ISPD (International Symposium on Physical Design), a group of Nvidia researchers presented a paper on AI-based macro placement. The paper proposes AutoDMP, a methodology that leverages DREAMPlace, a preexisting open-source GPU-accelerated placer, to place macros and standard cells concurrently in conjunction with automated parameter tuning using a multi-objective hyperparameter optimization technique. As a result, the team could generate high-quality predictable solutions, improving the macro placement quality of academic benchmarks compared to baseline results generated from academic and commercial tools. According to the Nvidia researchers, AutoDMP is also computationally efficient, optimizing a design with 2.7 million cells and 320 macros in three hours on a single Nvidia DGX Station A100. The key contributions of the work include using multi-objective Bayesian optimization to search the design space of macro placements, targeting three PPA proxy objectives post-place: wirelength, cell density, and congestion; using a two-level PPA evaluation scheme to manage the complexity of the search space; and enhancing the DREAMPlace placer. Open-source benchmarks used include Ariane, a single core Risc-V CPU; the MemPool Group and BlackParrot designs, many-core Risc-V CPUs with large amounts of on-chip SRAMs; and an NVDLA partition.
A previous research work on AI-based macro placement, from Google, had been criticized for not providing enough publicly available data and for comparing the AI performance to an unspecified human expert’s performance. The new Nvidia work seems to be able to withstand these types of criticism, as it includes details on benchmarking and compares the AI performance with a commercial EDA tool, Cadence Innovus. The work’s source code is released on GitHub.
Manufacturing-related innovations make up a large part of this week’s news roundup. Arm vs Risc-V is also a theme, with the open-source ISA gaining ground in China while Arm’s IP is reportedly set to become more expensive.
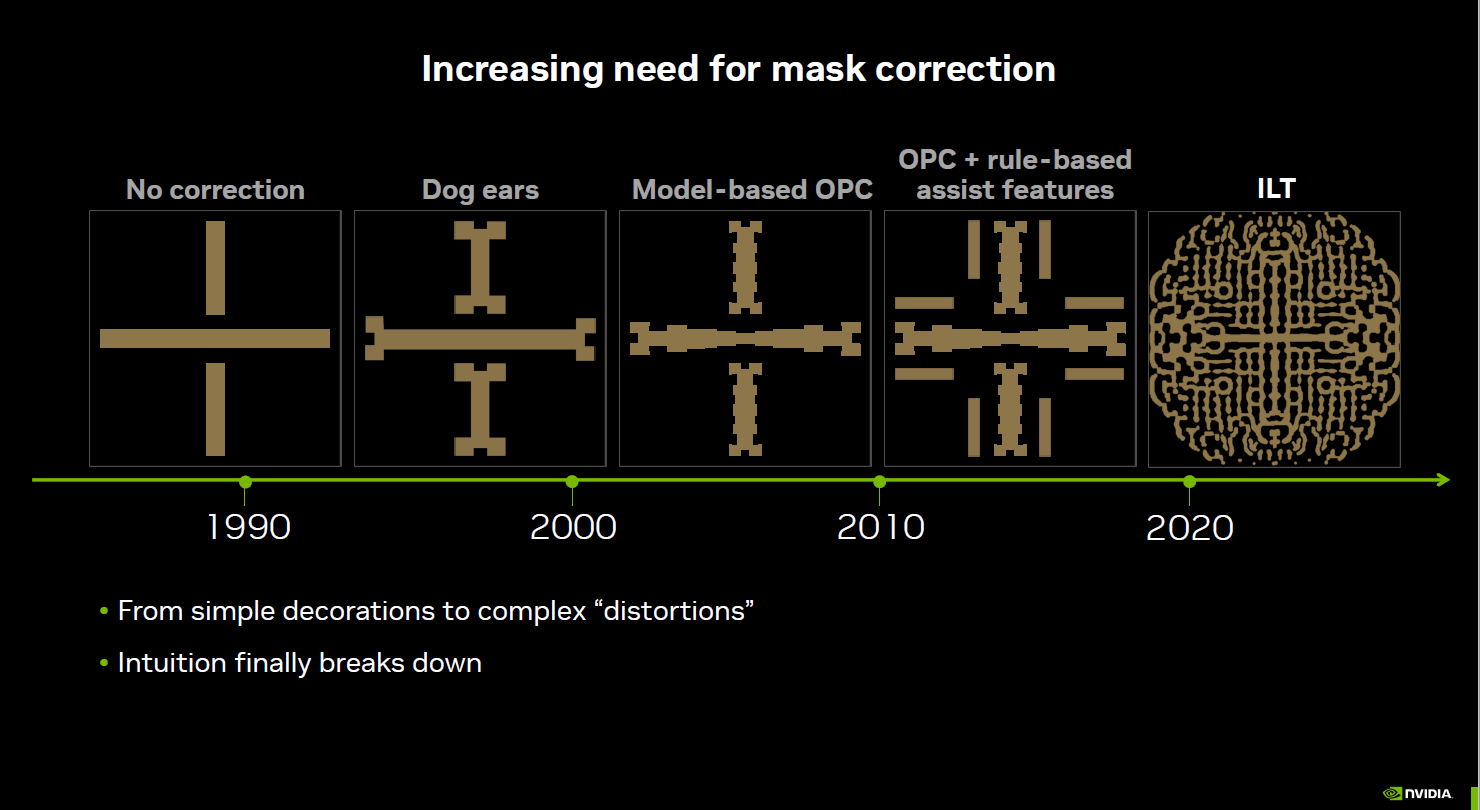
Nvidia cuts processing time for computational lithography
The new Nvidia cuLitho software library for computational lithography promises to slash the time and energy required to produce photomasks. Mask manufacturing at advanced nodes requires a vey complex compensation of the pattern distortions caused by the diffraction of light or EUV rays. Simplistically explained, the compensation is essentially obtained by transforming the design polygons into complex shapes, so that the combined effect of these shapes and diffraction will eventually result in the desired polygons being projected on the resist. This transformation – an example of computational lithography – is obviously carried out by software running on a processing platform. With large chips now containing several dozen billion transistors, foundries working on advanced nodes need large datacenters to perform computational lithography. As we learn from Jensen Huang’s keynote given at this year’s GTC event, TSMC is currently using a 40,000 CPU server farm for computational lithography, absorbing 35 megawatts. With cuLitho, and running all parts of the computational lithography process in parallel, the workload can be handled by just five hundred Nvidia DGX H100 GPU-based systems, reducing power to ‘just’ 5 megawatts. According to Nvidia, in the near term, fabs using cuLitho could produce each day 3-5x more photomasks using 9x less power than current configurations. A photomask that required two weeks can now be processed overnight.
Source: Nvidia GTC. ILT stands for Inverse Lithography.
The international race for semiconductor supremacy and the impact of electric vehicles on the SiC market are among the themes of this week’s news roundup. But first, some IP and EDA updates.
IP and EDA updates: Signature IP, Defacto, Cadence
New startup Signature IP aims to innovate the Networks-on-Chip IP scenario. As the company stated in a press release, the company’s purpose is to make it easy to design and configure the NoC backbone within a chip and benefit from the flexibility of exploring the design space before committing to an architecture. “There are few commercial NoC providers to choose from, and they are typically very restrictive in their architectures and commercial terms,” said CEO Purna Mohanty. “Our flexible iNoCulator NoC configuration tool enables customers to experiment with their SoC architecture and simulate it in real time so they can optimize it at the top level.” Offered as Software-as-a-Service, iNoCulator NoC Configurator can generate both coherent and non-coherent NoCs. It enables users to change the NoC topology, experiment with different configuration settings, and simulate the results to measure throughput and latency.
Defacto has announcedSoC Compiler 10.0, the new major release of its front-end design solution for large SoCs. Among new pre-synthesis design features, the ability to use both Accelera’s IP-XACT and RTL as input formats for internal and external IPs at different design steps; “ifdef” support to generate generic and configurable RTL code; a higher degree of automation in the management of design collaterals such as UPF and SDC jointly with RTL and IP-XACT; and Python native support.
The Netherlands’ government is reportedly planning new restrictions on exports of semiconductor technology. The restrictions will obviously impact ASML’s litho equipment, and – according to the report – will also affect DUV systems. More updates included in this week’s roundup concern automotive applications, foundry results, and upcoming European conferences.
Automotive updates: Ford, imec, proteanTecs
Ford Motor Company has established Latitude AI, a wholly owned subsidiary focused on developing automated driving systems. The move comes just a few months after the company shut down Argo AI, a self-driving technology unit that Ford ran in collaboration with Volkswagen. Latitude employs about 550 employees formerly of Argo AI and is headquartered in Pittsburgh – with additional engineering hubs in Dearborn, Michigan, and Palo Alto, California.
Belgian research center Imec has developed a digitally calibrated charge-pump phase-locked loop that can generate high-quality frequency-modulated continuous-wave signals for mmWave radars at low power consumption. The novel PLL is a critical building block for future short-range automotive (in-cabin and out-of-cabin) and industrial radar applications.
Catching up on some of the news from the last three weeks or so, let’s start with a Silicon Valley update: Tesla global engineering headquarters are moving to Palo Alto. The company is reportedly taking over the lease for the office space previously occupied by Hewlett-Packard. More news this week concern new fabs around the world and the U.S. CHIPS Act. But first, some IP and VIP updates.
IP, VIP and validation updates: Arteris, Avery, Cadence, Imperas
Arteris has launched its FlexNoC 5 physically aware network-on-chip IP, which enables SoC designers to incorporate physical constraint management across power, performance and area (PPA). According to the company, this technology enables up to 5X faster physical convergence over manual refinements with fewer iterations from the layout team. The resulting physically optimized NoC IP instance is ready for output to physical synthesis and place and route for implementation. Arteris has also formed a partnership with Risc-V IP vendor SiFive, to help speed up edge AI product development. As a result of this collaboration, SiFive has developed the 22G1 X280 Customer Reference Platform, incorporating a SiFive X280 processor IP and an Arteris Ncore cache coherent interconnect IP.
Avery Design Systems has announced a new validation suite supporting the Compute Express Link (CXL) open industry-standard interconnect. It enables system interoperability, validation and performance benchmarking of systems targeting the full range of versions of the CXL standard. According to the company, sharing the same validation suite across pre- and post-silicon enables hardware and software development teams to start system integration and validation extremely early in the project while still working with Verilog RTL simulation and emulation.







 Animation, 3D Art and 3D Models")